Chamber Cardio - case study

Chamber Cardio, a technology-enabled cardiology solution, helps enable and empower cardiologists and practices in their transition to value-based care. With our cloud-based technology platform, we offer a suite of tools designed specifically for cardiovascular care. These tools provide real-time insights, analytics and care coordination tools focused on improving outcomes for patients with chronic cardiovascular conditions.
Chamber’s products serve as a compliment to a cardiology practice’s existing Electronic Health Records (EHR) and Practice Management Systems offering many powerful features, such as quality measure and care gap assessment, customizable population-level patient dashboards and hospital encounter notifications, clinical pathway workflows (including guideline-directed medication support), automated risk assessments and care team collaboration through secure messaging and task management.
To reduce engineering lift and accelerate development, the clinical and operational front-end for internal care team management was built using the Retool Enterprise Platform self-hosted in Chamber’s AWS cloud environment integrated directly with Medplum for the backend data storage and web services layer.
Problem
In the early stages of product development, the Chamber team, with limited time and technical resources, sought out creative solutions to help accelerate product delivery without sacrificing the quality or capabilities in scope for our MVP milestones. We initially prioritized the development of our core data integration pipeline (including EHR, ADT feeds, claims, etc.) and a foundation for internal tooling to properly support clinical and operational workflows.
The complexity of internal care coordination and practice management requirements, including integrated clinical guidelines, medication titration support, disease-specific risk assessments, and quality measure reporting, elevated the challenge. We also had to manage and normalize diverse datasets and terminology standards. As a seed-funded startup with just two software engineers, finding the right mix of custom-built and off-the-shelf solutions was critical to building a strong, secure foundation for the product, capable of supporting future growth.
Solution
Chamber decided to tackle the challenge of managing key data workflows and operational tooling by leveraging Retool as the backbone for our internal platform. Retool's platform, known for its comprehensive frontend components and ease of data integration, enabled Chamber's team to effortlessly link our FHIR datastore, supported by Medplum, with clinical and scheduling information. This approach allowed for a development of a wide range of care management and operational applications with minimal custom development.
The Retool client, deployed in AWS, connects to Medplum directly, using both API protocols (REST and GraphQL). This configuration provided a flexible and robust environment for Chamber’s internal requirements, and, given the compliance offering (SOC 2, HIPAA, ONC, etc) from Medplum built into the platform, our team could devote more resources to developing a reliable data pipeline and a high-quality user experience for our external clinician-facing products, ensuring the foundation was set for future scale and complexity.
Challenges Faced
Several challenges emerged during the early development process:
- Normalizing Clinical Terminologies: One of the first obstacles was creating a system to accurately map and normalize clinical terminologies from various data sources into Chamber’s FHIR datastore. The solution was a blend of API integrations for standard coding systems, utilization of public crosswalk datasets, and leveraging Medplum for critical terminology metadata and mapping logic. This multilayered approach ensured a seamless, standardized coding solution.
- Generating Realistic Synthetic Patient Data: To refine complex workflows, Chamber turned to Synthea™, generating synthetic patient data that mimics real-world medical histories (e.g. hospital encounters, office visits, prescriptions, lab values, etc). This synthetic data allowed our team to simulate scenarios specific to chronic cardiovascular diseases, refining the system’s use of FHIR resources and Medplum integration. The insights gained were pivotal in developing analytics dashboards, risk assessment algorithms, and medication management features.
- Concept Mapping and Categorization: Effective query support and decision-making required a sophisticated grouping and categorization of clinical concepts. By integrating with leading coding system APIs and the NLM VSAC repository through Retool, Chamber was able to categorize and code clinical concepts efficiently, laying the groundwork for robust data queries and decision support tools.
- Maximizing Retool Built-in Capabilities: While Retool provided a strong foundation for data integration, Chamber encountered limitations with more complex and nuanced FHIR data use cases. To overcome these, the team incorporated FHIR-based libraries as global functions using BonFHIR, enhancing Retool’s capabilities while adhering to healthcare standards.
Medplum Features
Medplum, offered several key features that were useful in the development of the Chamber Cardio platform:
- Authentication: Ensuring secure access and access controls for data and system functionality that works well with Retool.
- Subscriptions: Used to automate critical updates when changes are made to FHIR resources, helping to maintain quality and contingency across all data elements.
- API and SDK: Offering robust application programming interfaces and software development kit for seamless integration.
- Compliance: Meeting healthcare regulations and standards, an essential aspect of any medical software solution.
Retool Features
Chamber took advantage of a wide array of Retool’s platform capabilities for both prototyping and developing solutions for internal tools and care coordination workflows:
- Component Library: comprehensive set of highly customizable, scalable and responsive frontend components
- Data Source Integration: REST and GraphQL APIs, AWS Lambda, S3 Resources
- Javascript Transformers: reusable functions and local data storage used to manipulate data returned from queries and access anywhere in the app
- Event handling: triggering queries and components on successful and failing query responses and manual data refresh control
- Environments & Version Control: Ease of configuration for multi-environment deployment with dedicated data sources and version-based release support
- Self-Hosted Deployment: To maintain healthcare compliance, Chamber’s Retool instance is deployed fully within our AWS cloud infrastructure
Conclusion
Chamber Cardio’s initiative underscores the effectiveness of combining cutting-edge technologies—Retool’s frontend versatility, Medplum’s backend strength, and BonFHIR’s supplementary libraries and tooling —to craft a cardiology care platform that stands out for its comprehensive data integration and workflow management offering. This collaboration resulted in a product and technology foundation for enhanced care coordination, streamlined decision-making processes, and a supportive pathway for cardiology practices transitioning to value-based care and exemplifies how strategic tool selection and technology partners can enable meaningful advancements in healthcare innovation and delivery.
References
- Chamber Cardio Blog Post on Modernizing Cardiology Care


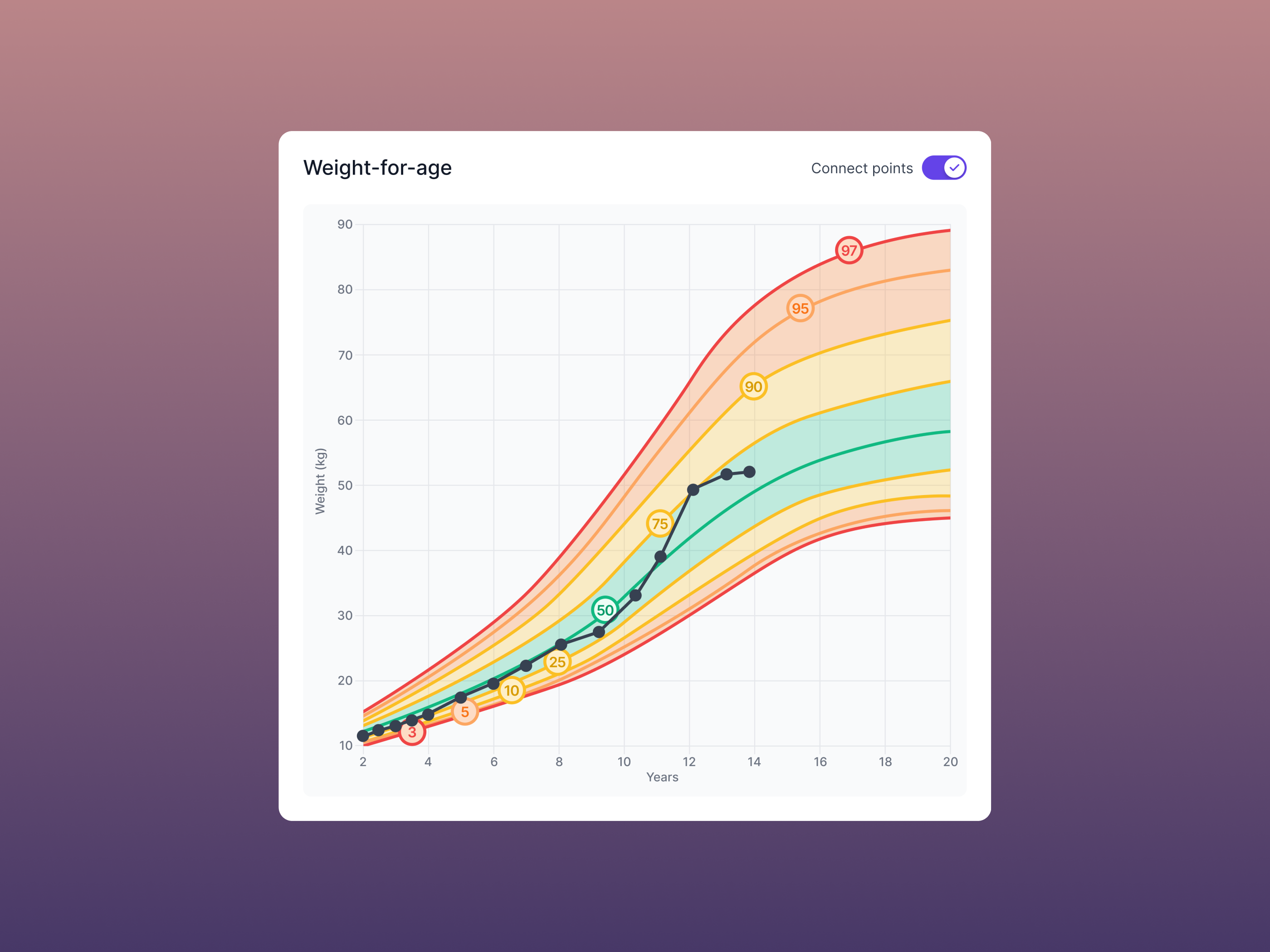 (A beautiful pediatric growth chart)
(A beautiful pediatric growth chart)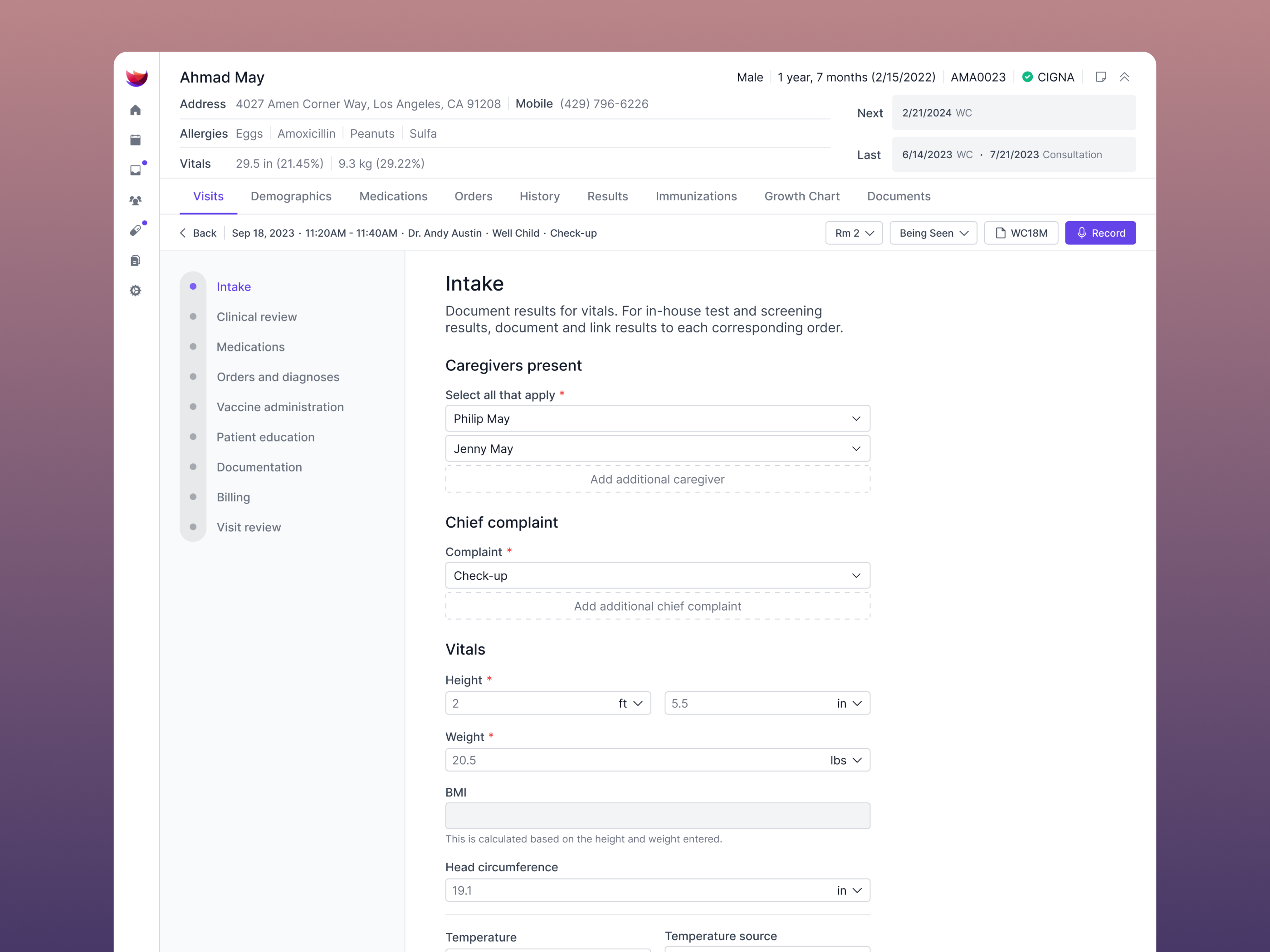 (Intuitive patient intake)
(Intuitive patient intake)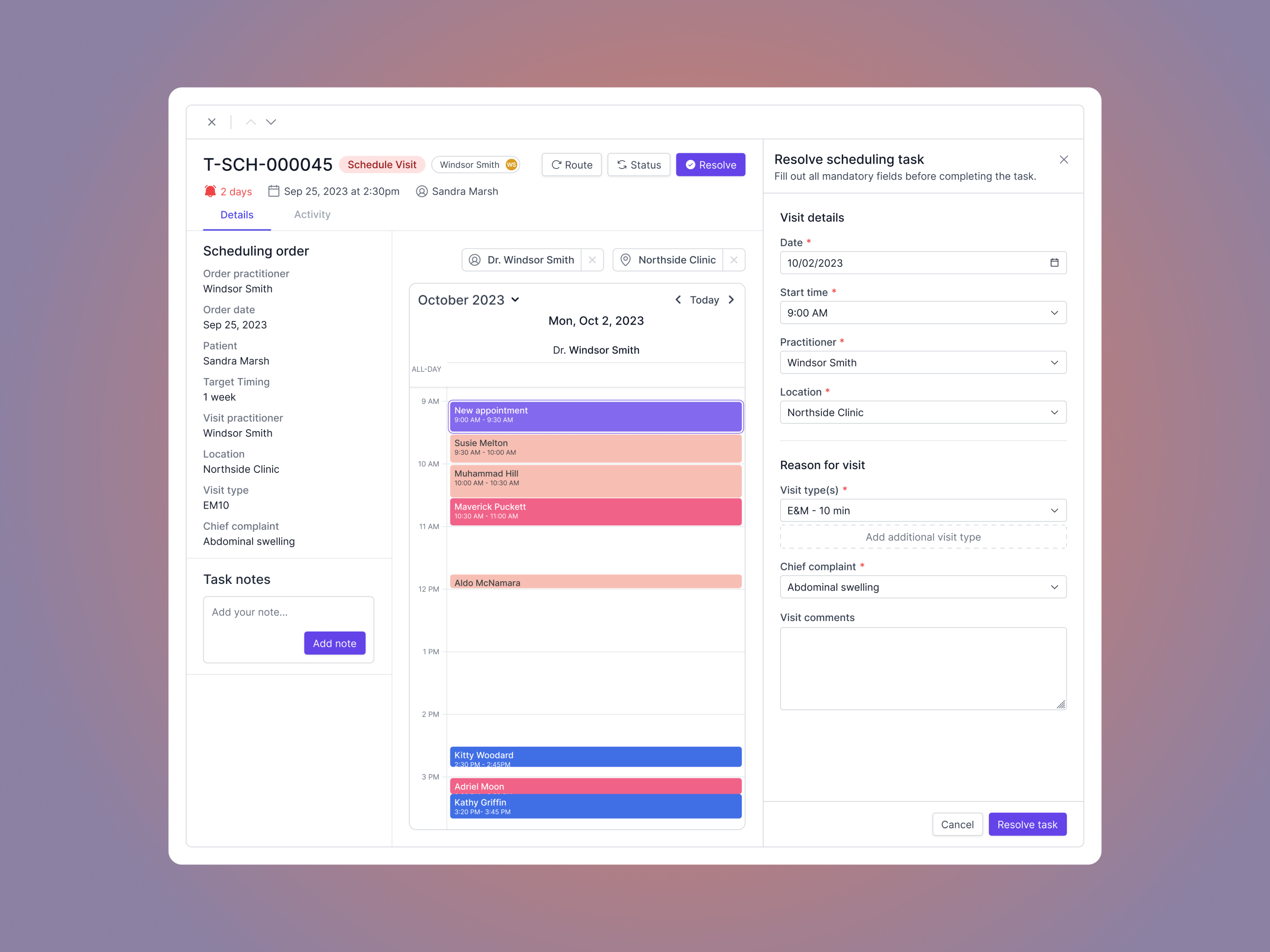 (Scheduling orders)
(Scheduling orders)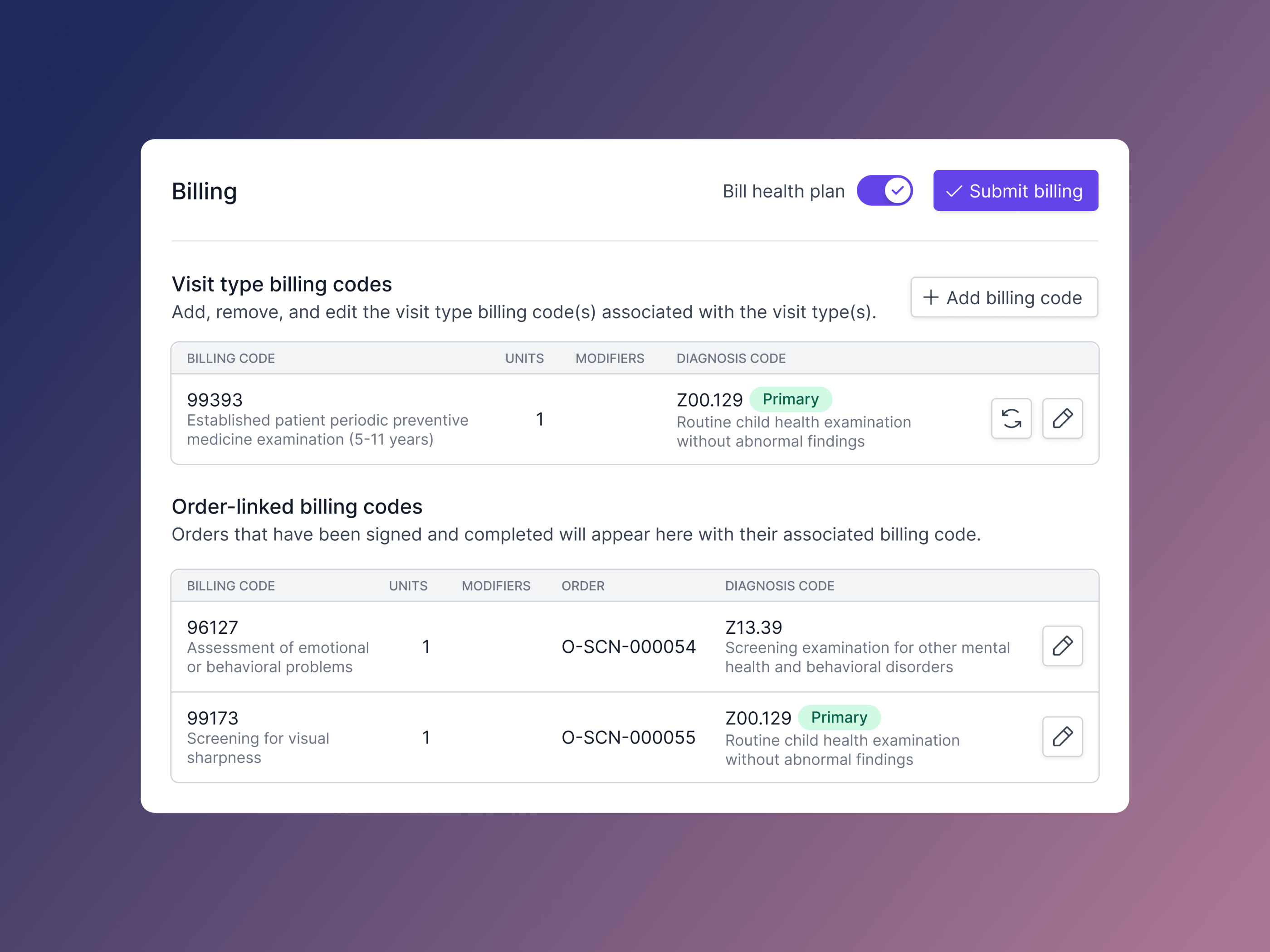 (Even the billing experience shows attention to detail)
(Even the billing experience shows attention to detail)